原生多模态模型 LongCat-Next 及离散分词器正式开源
大模型研发团队近日发布并开源了 LongCat-Next 模型及其核心离散分词器。当前主流大模型多依赖语言底座,通过外挂视觉或语音模块实现多模态功能。该团队将底层架构重构为 DiNA(离散原生自回归)模式,把图像、声音和文字统一转化为同源离散 Token。所有模态共享同一套参数、注意力机制与损失函数。视觉与听觉任务在数学形式上统一为下一 Token 预测,模型因此不再需要拼接外部组件。
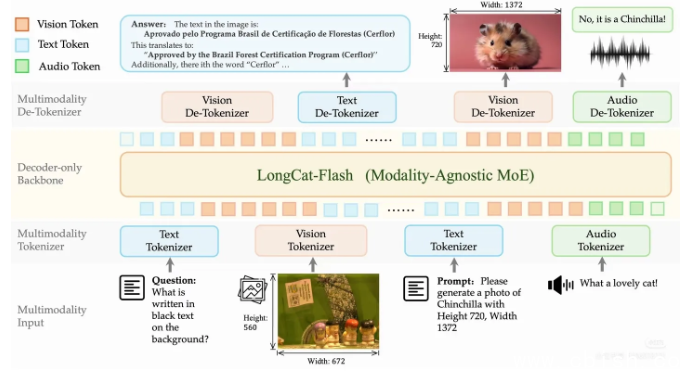
视觉编码部分采用 dNaViT(离散原生分辨率视觉分词器)。该技术允许输入任意原生分辨率,在处理文档解析和复杂图表时能保留更多细节。系统通过 8 层残差向量量化机制完成 28 倍的像素空间压缩,并由解耦双轨解码器保证还原保真度。这构成了图像与 Token 之间的完整转换闭环。针对业界普遍认为离散化会损失信息的问题,团队引入 SAE(语义对齐编码器)对特征进行层级拟合,使离散表示能够逼近高维连续数据。模型基座为 LongCat-Flash-Lite MoE 结构,总参数量 68.5B,激活参数量 3B。
测试数据显示该架构具备跨模态处理能力。在 OmniDocBench 评估中,模型得分超过 Qwen3-Omni 与专用视觉模型 Qwen3-VL。纯文本能力未受多模态统一训练影响,在 MMLU-Pro 与 C-Eval 榜单中维持领先。SWE-Bench 的工具调用和代码生成测试也优于同类模型。音频方面,模型在 SeedTTS 中英文语音合成任务中误字率较低,支持低延迟并行文本转语音与个性化语音克隆。项目代码与权重已上传至 GitHub 与 HuggingFace。