AWS为了帮助更多企业将数据从其他公有云迁移到AWS环境,在官方技术博客中介绍了一套分布式跨云数据迁移架构。该架构结合开源命令行数据同步与迁移工具rclone,以及Amazon ECS、Amazon SQS、EC2 Auto Scaling和CloudWatch等AWS服务,应对PB级数据跨云迁移过程中常见的进度追踪、失败重试和规模扩展挑战。
AWS指出,当企业需要在不同云服务提供商之间迁移PB级数据时,传统单机或集中式数据传输方式往往面临进度难以掌握、失败后重启流程繁琐、频繁人工干预等问题。若在迁移过程中还需加入自定义标签或其他业务逻辑,将进一步延长迁移时间,并增加数据漂移风险与成本。
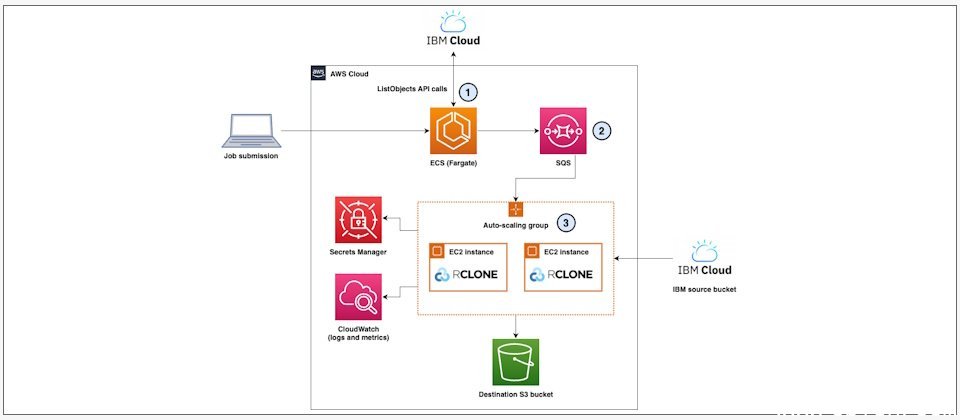
这套跨云数据迁移架构主要分为探索层(Discovery Layer)、队列层(Queueing Layer)与执行层(Execution Layer)。探索层通过Amazon ECS搭配AWS Fargate运行,自动列举源存储系统中的对象,并将文件每20个为一组打包成批次任务,交由Amazon SQS队列分发给后续工作节点处理。
在执行层,SQS将每个批次作为独立任务,分配给EC2上的rclone工作节点。AWS在该架构中使用r5n.xlarge实例构建Auto Scaling组,并根据SQS队列中的待处理任务量自动扩展或缩减工作节点规模。每台实例可同时运行6个rclone进程,以提升网络带宽利用率。
AWS表示,该设计通过SQS的可见性超时(visibility timeout)与死信队列(dead-letter queue)机制,使临时失败的任务自动重新入队重试;若任务两次尝试后仍失败,则会被移入死信队列,便于后续排查,从而减少人工干预和运维负担。同时,通过CloudWatch日志与自定义指标,可实时追踪文件传输进度、失败批次及传输耗时等迁移情况。
在实际测试中,AWS使用容量为2.7 PB的媒体归档数据集,从IBM Cloud Object Storage迁移至S3。整个工作节点集群达到15~120 Gbps聚合吞吐量,Auto Scaling组约10分钟内扩展至5台EC2实例,整体迁移耗时约两周,计算成本约为2000美元。
AWS指出,由于该架构采用兼容S3 API的设计,因此除IBM Cloud Object Storage外,也可应用于Google Cloud Storage和Azure Blob Storage等服务。用户仅需调整端点配置及AWS Secrets Manager中的源端凭证,无需重新部署整体架构。
此外,AWS解释选择rclone而非直接使用AWS SDK的主要原因,在于rclone提供了统一的跨S3兼容存储服务命令行接口,避免为不同云厂商分别编写专属SDK代码,从而降低多云迁移时的开发与维护复杂度。