微软Foundry Local正式推出,这是一套跨平台的本地端AI推理方案,让开发者通过SDK将AI模型直接嵌入应用程序,在用户设备上离线执行推理,无需云端连接,也不会产生额外的Token计算费用。
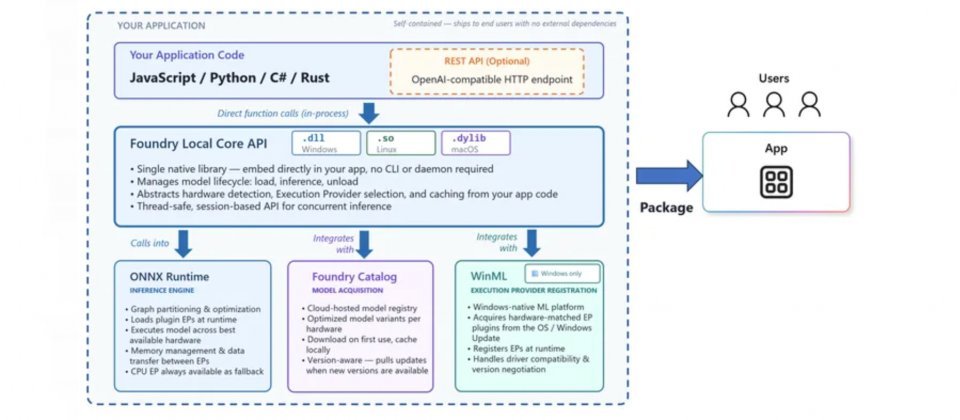
Foundry Local让开发者可将AI推理能力随应用程序一同发布。开发者安装SDK后,Foundry Local Core与ONNX Runtime的执行文件会在构建阶段自动集成到应用程序中。微软表示,该方案体积精简,不会明显增加安装包大小,终端用户无需额外安装CLI工具或第三方软件,即可直接使用AI功能。
其支持Windows、macOS与Linux。Windows版本整合Windows ML(WinML)进行推理,并通过Windows Update自动获取与硬件匹配的执行提供程序插件,以解决驱动兼容性问题。macOS版本原生支持Apple Silicon,通过Metal实现GPU加速。Foundry Local会自动检测硬件环境,智能选择使用GPU、NPU或CPU执行推理,开发者无需额外编写硬件检测逻辑。
在SDK方面,Foundry Local提供Python、JavaScript、C#与Rust四种语言支持,推理API采用与OpenAI兼容的请求与响应格式,涵盖聊天完成(Chat Completions)、音频转录及Open Responses API。微软表示,这使开发者能在云端与本地推理之间无缝切换,无需额外搭建本地HTTP服务器;若应用场景需要REST调用,也可在初始化时选择启用与OpenAI兼容的HTTP端点。
由于Foundry Local整合了Foundry Model Catalog,应用程序首次运行时会从目录下载针对设备硬件优化的模型,后续则从本地缓存加载。目前支持的模型系列包括GPT OSS、Qwen、Whisper、DeepSeek、Mistral与Phi,同时支持断点续传下载机制,用户即使中途关闭应用或断网,下次启动时仍可从中断处继续下载。
在微软的AI部署架构中,Foundry Local负责设备端推理,可在手机、笔记本与台式机等终端设备上运行模型;云端则由Microsoft Foundry提供高级模型、AI代理与微调服务。至于结合Azure Local的Foundry Local部署方案,目前仍处于预览阶段,主打将这些模型与代理式AI部署到用户自有的分布式基础设施中。
微软也公布了后续发展方向,包括扩展模型目录、实时麦克风语音转录、更广泛的NPU与GPU硬件支持,以及优化共享缓存机制,让多个应用程序能共用已下载的模型。Foundry Local的代码示例现已在GitHub公开。