
微软本周发布新版桌面模型Phi-4-reasoning-vision-15B,兼具轻量、多模态与推理能力,可执行视觉识别与文本理解、数学及科学推理等多种任务。目前相关权重与资源已在GitHub和Hugging Face平台公开。
Phi-4-reasoning-vision-15B基于Phi-4和Phi-4-Reasoning语言模型,并加入多模态训练。微软在设计时刻意避免过度依赖大规模数据集、复杂架构,或在推理阶段生成过多token,以降低视觉语言模型(VLM)常见的高延迟、部署困难和资源消耗问题。
与Qwen 2.5 VL、Kimi-VL和Gemma3等模型动辄使用上万亿token训练不同,Phi-4-reasoning-vision-15B仅使用约2000亿token的多模态数据,并采用SigLIP-2视觉编码器与Phi-4-Reasoning作为核心架构完成训练。
在仅150亿参数的规模下,该模型仍可在普通硬件上运行,同时具备结构化推理能力,支持多种任务,包括图像描述与字幕生成、图片问答、文档阅读与食谱解析等。此外,模型还具备数学与科学推理能力,能够理解电脑和手机屏幕上的内容。
图片来源/微软
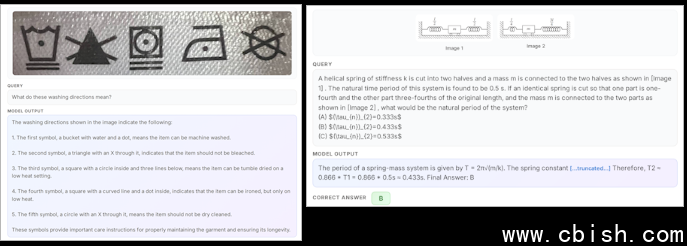
微软还提供了诊断准确性评估Eureka ML Insights和多模态准确性评估工具VLMEvalKit的结果,显示与Qwen 2.5 VL、Kimi-VL和Gemma3等常用开源思维模型相比,Phi-4-reasoning-vision-15B在混合推理行为上的得分更高,表明其能更平衡地处理思维与非思维行为,进一步提升准确性与计算效率。
目前,Phi-4-reasoning-vision-15B已在Microsoft Foundry、Hugging Face和GitHub平台公开。