GLM-5 正式发布:国产大模型的里程碑时刻
春节刚过,AI圈就被一条消息刷屏了——智谱科技正式推出新一代大模型 GLM-5。没有花哨的发布会,没有明星代言,但它的出现,让无数开发者、企业用户和科技爱好者一夜之间开始重新评估国产AI的潜力。
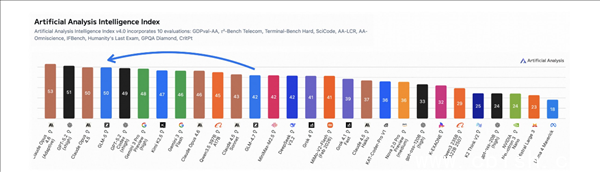
GLM-5 不是简单的“参数堆砌”。它的参数量达到7440亿,几乎是前代GLM-4.X的两倍。但这不是终点,而是起点。真正让人眼前一亮的,是它在编程任务上的表现——在权威的Agent编程评测中,GLM-5 一举拿下全球第一,综合编程能力稳居全球前三,超越了多个国际主流模型。不少程序员在试用后反馈:“它写代码的逻辑更像人,不是机械复制,而是能理解上下文、主动优化结构。”
算力告急,用户排队,说明它真火了
模型一上线,服务器就扛不住了。短短两天,智谱科技的API调用量暴涨数倍,大量用户反馈“排队等待”“响应太慢”。这不是技术事故,而是市场用脚投票的结果。
智谱很快发布致歉信,承认资源紧张,并宣布将逐步扩容服务器,同时为受影响的用户发放免费调用额度。一位开发者在社交媒体上写道:“我等了40分钟才跑通一个脚本,但结果比我用GPT-4还顺手——值了。”
这不是一场“秀技术”,而是一场真实的用户验证。当一个模型能让普通人愿意等、愿意试、愿意推荐,它的影响力就已经超越了实验室。
不靠国外芯片,也能跑出顶尖性能
GLM-5 最让人意外的,不是它有多强,而是它“能跑在哪”。它成为首个全面适配七大国产AI芯片的千亿级大模型——华为昇腾、寒武纪MLU、摩尔线程、海光DCU、天数智芯、壁仞科技、沐曦集成电路,全部支持。
这意味着什么?意味着你不用再依赖英伟达的H100,也能在国产服务器上跑出接近国际顶级集群的性能。更关键的是,GLM-5 在长文本处理上的部署成本直接砍掉一半。对于需要处理数万字合同、法律文书、技术文档的企业来说,这不只是省钱,更是效率的跃升。
有企业IT负责人透露:“我们原本计划采购一批A100,现在改了方案,准备先上昇腾910B集群,配合GLM-5做内部知识库。成本省了40%,性能不输。”
背后的四个“实打实”的改进
GLM-5 的突破,不是靠宣传,而是靠底层重构:
- 稀疏注意力机制:不是所有文字都值得“认真看”。GLM-5 能自动识别哪些词是关键信息,哪些可以“略读”,训练和推理效率大幅提升,响应更快,耗能更低。
- 异步训练系统:过去模型训练时,生成和学习要“同步排队”,GPU经常空等。现在,它能一边生成答案,一边自己学习错误,GPU利用率直接拉满。
- 自主学习的智能体算法:它不再只是“回答问题”,而是能像人一样“试错”。比如写一个爬虫,跑不通就自己改参数、查日志、找替代方案,直到成功。这不是预设脚本,是真正的动态进化。
- 国产芯片深度优化:不是“能跑”,而是“跑得好”。每一款芯片都有专属的算子优化,不是简单移植,而是从底层重构计算路径。
这些改动,没有炫酷的术语,但每一个都直击实际痛点:慢、贵、难部署、依赖进口。
它不是终点,而是国产AI的起点
GLM-5 的出现,让很多人第一次意识到:我们不是在追赶,而是在构建自己的生态。
它没有喊“颠覆世界”,但它让开发者能用国产设备,跑出比肩国际的性能;它没有承诺“取代GPT”,但它让企业愿意把核心业务交给它处理;它没有搞明星发布会,但它的用户群,正在悄悄扩大。
有人问:它能替代ChatGPT吗? 答案可能不是“能”或“不能”,而是——“我们终于有了选择。”
接下来的几个月,将是GLM-5 的真实考场:谁在用?怎么用?能稳定跑多久? 但有一点已经明确:国产大模型,不再是实验室里的展品,它正在走进真实世界。