独立模型评测机构Artificial Analysis更新了智慧指标(Intelligence Index)至v4.0,调整了评测组合,使评测重点更贴近实际任务与可靠性行为。官方同时提醒,综合指标可用于模型间的比较,但仍存在局限,未必能直接适用于每一个使用场景,并在方法论中强调评测应兼顾公平性与真实世界适用性。
Intelligence Index v4.0移除了MMLU-Pro、AIME2025与LiveCodeBench等常见测试,改用新的评测组合,试图重新拉开模型之间的差距。
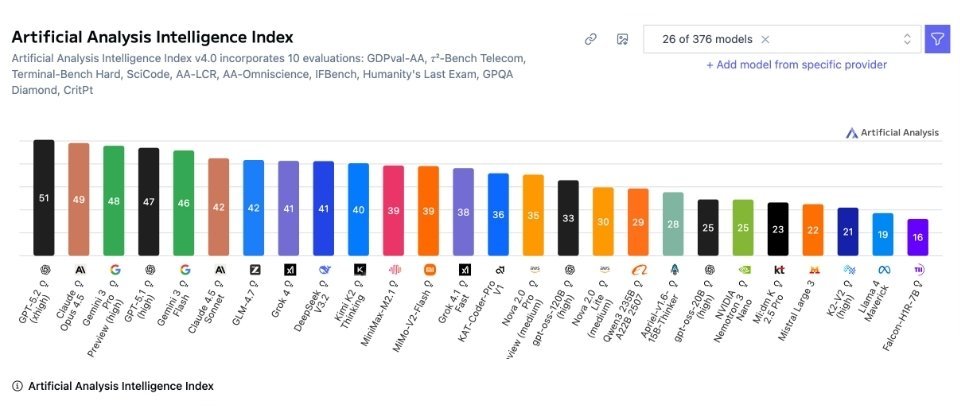
在Intelligence Index v4.0的前26个模型中,GPT-5.2(xhigh)以51分位居榜首,Claude 4.5 Opus为49分,Gemini 3 Pro Preview(high)为48分,GPT-5.1(high)为47分,Gemini 3 Flash为46分。第二梯队大致落在40分上下,包括Claude 4.5 Sonnet与GLM-4.7均为42分,Grok 4与DeepSeek v3.2均为41分,Kimi K2 Thinking为40分。其后分数逐步拉开,末尾模型已降至20分以下,例如K2-V2(high)为21分,Llama 4 Maverick为19分,Falcon-H1R-7B为16分。
v4.0备受关注的新增项目之一是GDPval-AA,该评测基于OpenAI提出的GDPval数据集,题目取自专业人士的真实工作产出,涵盖44种职业与9大行业,用于评估模型在具有经济价值的知识型工作任务上的表现。OpenAI指出,这类任务更能清晰反映模型是否真正能支持日常工作,而不仅仅是正确回答题目。
AA-Omniscience通过包含6000道题目、覆盖六大领域共42个主题的题库,衡量模型的知识准确性与幻觉行为,并采用扣分机制惩罚盲目猜测,同时对不作答保持中性评分,以鼓励模型在不确定时选择不回答。Artificial Analysis也指出,高正确率并不必然代表低幻觉率,且不同领域的领先模型各不相同,选择模型仍需结合具体应用场景。
在科学推理方面,新增了CritPt评测,主打未公开的研究级物理推理挑战,由50位以上在职研究人员共同设计。Artificial Analysis公布的CritPt排行榜显示,目前表现最佳的模型正确率也仅约一成出头,例如GPT-5.2(xhigh)为11.6%,其余多数知名模型均落在个位数百分比甚至接近零,表明模型在运用长链推理获得可验证最终答案方面仍有很长的路要走。
当系统允许使用程序执行与网页搜索等工具后,模型的正确率有所提升,但CritPt研究团队同时指出,这种工具辅助仅带来小幅进步,仍不足以突破核心推理瓶颈。
不过,Artificial Analysis再次提醒,任何排名都只能作为参考起点,最终仍需以自身数据、流程与风险阈值进行验证。