OCR 已经不够用了,Mistral OCR 3 正在重新定义“文档理解”
如果你用过市面上主流的 OCR 工具,大概率有过这样的经历:扫描一份合同、发票或手写笔记,结果识别出一堆错字、乱码,表格被拆得七零八落,手写部分干脆直接丢弃。不是识别不准,而是它根本“看不懂”你给的是什么。
Mistral AI 最新发布的 Mistral OCR 3,不是另一个“识字更准”的升级版,而是一次从“识别文字”到“理解文档”的彻底跃迁。它不追求泛用性,而是专攻那些让传统 OCR 惨败的场景——低分辨率扫描件、多层合并表格、填满手写的申请表、年代久远的档案信件。
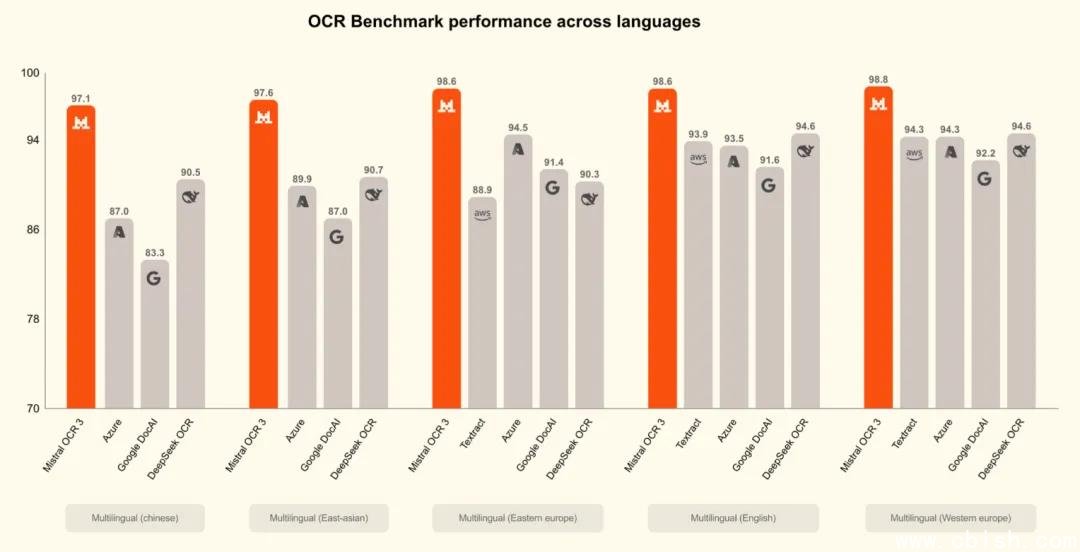
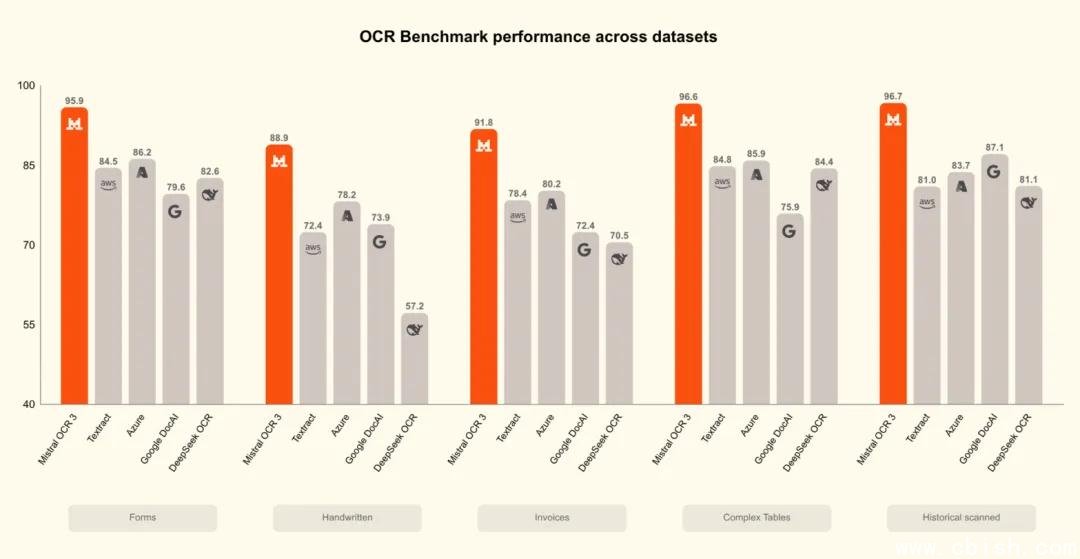
74%胜率不是吹的,实测碾压企业级方案
Mistral 官方公布的测试数据来自真实业务场景:2000+份来自财务、医疗、教育和政府机构的扫描文档,涵盖模糊印章、墨迹洇染、倾斜扫描、手写批注等极端情况。
对比 Mistral OCR 2、ABBYY FineReader、Google Document AI、Amazon Textract 等主流方案,OCR 3 在结构还原准确率上平均高出 18–25%,整体胜率达 74%。尤其在“合并单元格识别”和“手写文本可读性”两个维度,优势明显。
一个典型案例:一份手写填写的美国 IRS 1040 表格,OCR 3 不仅准确识别了所有字段,还自动匹配了对应行和列,甚至还原了用户在“备注栏”用铅笔写的补充说明——而其他工具要么漏掉,要么把字迹当成噪点过滤。
每千页只要1美元,性能和价格双杀市场
性能上,单节点每分钟可处理约 2000 页文档,支持并行批处理。更惊人的是定价:普通 API 调用为每 1000 页 2 美元,使用批处理接口(Batch API)可压至 1 美元/千页。
作为参考,Google Document AI 的标准定价是 1.5 美元/页(即 1500 美元/千页),ABBYY 的企业方案动辄数万美元年费。Mistral OCR 3 的价格,几乎是以“开源模型”的成本在做商业级服务。
有开发者在 Hacker News 上实测后表示:“我用它处理了 5 万页历史档案,成本不到 50 美元,而以前用商业方案要花 700 多。”
不只是文字,是完整的文档结构
Mistral OCR 3 的核心突破,是输出不再是“一串乱码文本”,而是带语义的结构化数据:
- 表格 → 自动重建为 HTML 表格,保留合并单元格、跨页延续、标题行
- 普通文本 → 输出为结构清晰的 Markdown,保留标题、列表、段落层级
- 整份文档 → 一键生成 JSON,字段名自动推断(如“收款人”“金额”“日期”)
这意味着,你不再需要额外写脚本去“清洗”OCR 结果。比如财务人员上传一张报销单,系统直接返回:
```json { "invoice_number": "INV-2025-001", "date": "2025-03-15", "amount": 890.5, "payee": "张三", "items": [ {"desc": "办公用品", "cost": 120}, {"desc": "打印纸", "cost": 75} ], "handwritten_notes": "已核对,发票原件已归档" } ```这种能力,让 OCR 从“输入工具”变成了“数据管道”的起点。
手写识别,终于不再是“勉强能看”
手写内容一直是 OCR 的“黑洞”。大多数工具要么完全忽略,要么把连笔字识别成“sdfghjkl”。
Mistral OCR 3 使用了专为手写设计的多模态模型,结合笔画动态特征与上下文语义推理,对潦草字迹的识别准确率提升近 3 倍。官方演示中,一封“圣诞老人来信”被完整解析,连孩子用蜡笔涂改的痕迹都被保留为注释。
在 Reddit 的 r/History 和 r/DigitalHumanities 板块,大量用户正在用它数字化家族信件、19世纪日记、战地档案。一位历史学者写道:“我花了三年手动转录 200 封二战士兵家书,现在 Mistral OCR 3 一小时就处理完了,准确率比我高。”
开箱即用,无需训练,老项目无缝迁移
你不需要懂 AI,也不用训练模型:
- 开发者:直接调用 API
mistral-ocr-2512,支持 PDF、JPG、PNG,返回 JSON/Markdown/HTML - 普通用户:登录 Mistral AI Studio 的 Document AI Playground,拖拽文件,一键生成可编辑文本或结构化数据
官方确认:OCR 3 与 OCR 2 的输入输出格式完全兼容,现有系统升级只需改个模型名,无需重构代码。
不只是效率,是数据资产的重生
企业档案、医院病历、法院卷宗、图书馆古籍——这些“沉睡的文档”过去只能存进硬盘,无法检索、无法分析、无法联动。
Mistral OCR 3 让它们第一次真正“活”起来:
- 财务团队:自动提取发票 → 对接 ERP 系统 → 一键报销
- 律所:扫描判决书 → 生成可搜索数据库 → 快速检索类似案例
- 教育机构:批量扫描学生手写作业 → 自动生成错题分析报告
- 研究者:将 10 万页手写信件转为结构化数据 → 用 LLM 分析情感变化趋势
这不是“更快的 OCR”,而是一场文档数字化的范式转移。当结构化数据能像数据库一样被查询、被关联、被自动化处理时,那些被遗忘在扫描仪里的纸张,才真正成为可增值的资产。
目前,Mistral OCR 3 已上线 API,免费额度每日 50 页,适合个人用户试用。企业用户可申请白名单,获取定制化部署方案。如果你手头正堆积着一堆“看不清、用不了”的扫描件——现在,是时候让它们重生了。