OpenAI于周二(12月16日)发布了全新的科学基准测试FrontierScience,用于评估AI在物理、化学与生物等领域执行专家级科学推理与研究任务的能力。
OpenAI解释,2023年11月推出的由博士级专家撰写的科学基准GPQA中,GPT-4仅获得39%的正确率,低于人类专家70%的平均分;而到2025年,GPT-5.2在GPQA上已取得92%的分数。这显示出模型能力的快速进化,使得原有以选择题为主、难度趋于饱和的科学测评已不足以衡量AI是否真正能够加速科学研究。
FrontierScience的双轨评估体系
由物理、化学及生物领域的专家撰写并验证的FrontierScience基准测试,包含数百道具有高难度、原创性与实质科学意义的题目,设计了两种不同的评估方向。
一是衡量奥林匹克竞赛风格科学推理能力的Olympiad模块,题目由国际奥赛奖牌获得者设计,为短答题形式,用于评估模型在受限条件下能否进行精确、严谨且可验证的科学推理。
二是衡量真实世界科学研究能力的Research模块,由博士级研究人员设计,题型为多步骤、开放式的科研任务,要求模型分析问题、展开推理并给出完整解释,并通过10分制量表评估其推理过程与结论的合理性。
模型表现对比
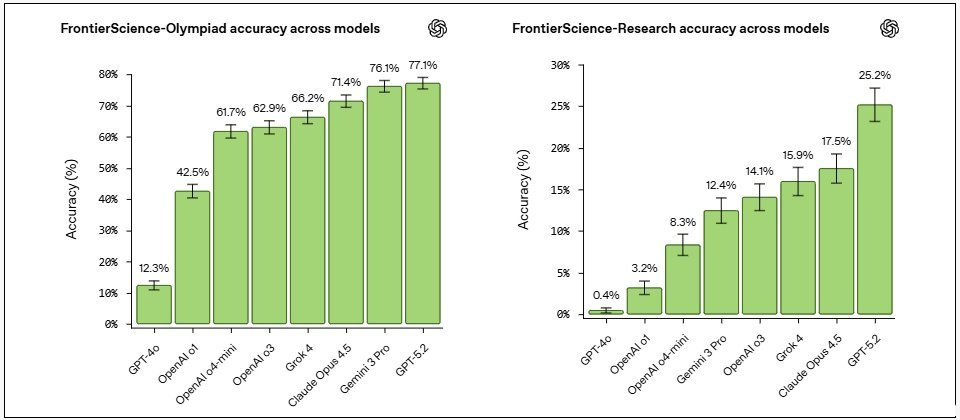
GPT-5.2在Olympiad模块中得分为77%,领先于Gemini 3 Pro的76.1%、Claude Opus 4.5的71.4%和Grok 4的66.2%;在Research模块中得分为25%,大幅领先Claude Opus 4.5的17.5%、Grok 4的15.9%和Gemini 3 Pro的12.4%。
对科研人员而言,这表明现有模型已能支持科研中涉及结构化推理的部分,但在开放性思维与创造性探索方面仍有巨大提升空间。
OpenAI认为,衡量AI科学能力最重要的标准,应是其能否促成全新的科学发现。FrontierScience并非最终验证工具,而是一个用于在研究成果出现前,评估模型推理能力进展、识别不足之处的评测基准,帮助研究团队确认模型是否朝着正确方向发展。