美国非营利研究机构AI2发布了新一代语言模型家族Olmo3,主打真正开源的思维模型。与多数仅发布最终权重的模型不同,Olmo3公开了训练数据、代码、评估流程,以及各阶段的检查点和用于回溯推理过程的工具,使外部团队能够完整复现并扩展该模型。
Olmo3家族提供70亿(7B)和320亿(32B)参数两种规模的模型,所有模型均以支持约6.5万Token上下文的基础模型Olmo3-Base为根基,并根据用途分化为思维、对话与强化学习版本。Olmo3-Think在基础模型上加入了多步推理训练,用于生成可检查的推理步骤;Olmo3-Instruct则强化了对话能力、指令遵循与工具使用;Olmo3-RL Zero专为强化学习研究设计,提供了多个领域的RL检查点。开发者可直接使用Instruct或Think版本,也可从Base或任一训练阶段入手,加入自己的数据继续训练。
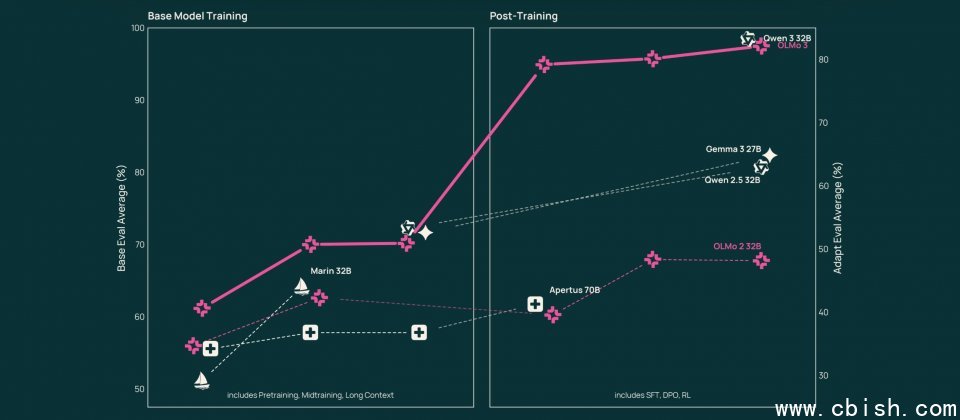
Olmo3家族中最具代表性的模型是32B规模的思维模型Olmo3-Think。该模型在回答问题时会生成中间推理步骤,并可通过OlmoTrace工具将推理过程回溯至可能相关的训练数据,帮助研究者理解模型做出特定判断的原因。根据AI2公布的评测结果,Olmo3-Think 32B在MATH、BigBench Hard、HumanEvalPlus等数学与编程推理基准上,多数指标接近Qwen3 32B与Qwen3 VL 32B Thinking,同时显著优于Gemma3 27B Instruct及部分同类模型。
AI2将32B基础模型称为目前最强的完全开源基础模型,即训练数据、代码与权重均可获取。与Mistral 32B、Apertus 70B等开源模型相比,Olmo3-Base在编程开发、阅读理解、数学解题和长上下文任务上的多数指标表现领先,与Qwen2.5 32B、Gemma3 27B和Llama3.1 70B实力相当,并具备处理长篇报告和技术文档的能力。
之所以称Olmo3为“真正开源”,是因为AI2一并公开了数据与工具。Olmo3的预训练使用Dolma3语料库,该语料库规模约为9.3万亿Token,来源涵盖网页、学术PDF、代码库与数学题解。AI2从中构建了Dolma3 Mix、Dolma3 Dolmino与Dolma3 Longmino等不同训练阶段的数据组合,后训练则使用Dolci数据套件支持推理、工具使用与强化学习。这些配方与数据集均在开放授权下公开,并详细说明了数据筛选与去重方法。