Meta发布新一代图像理解模型SAM 3,并同步推出面向3D世界的SAM 3D,将原本聚焦于二维图像分割的技术扩展至目标检测、视频追踪与3D重建。官方开放了SAM 3的模型权重、研究论文与微调代码,并推出Segment Anything Playground,让研究人员和内容创作者可在浏览器中直接试用。
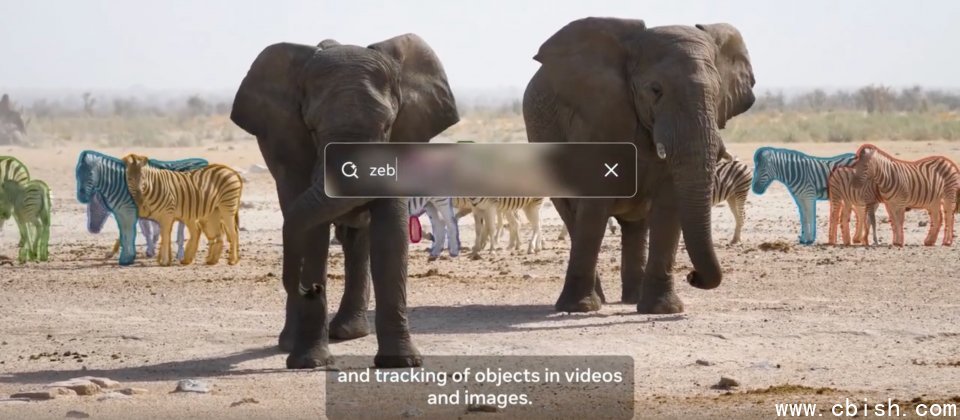
SAM 3最大的突破是支持用户使用简短文本提示进行分割,例如“条纹红色雨伞”或“手上没有拿礼盒的人”,模型能根据描述在图像或视频中识别所有符合的实体,为每个实例生成掩码并保持追踪ID。若目标难以用文字描述,用户也可提供示例图像,让模型通过外观比对进行识别。
Meta构建了结合AI与人工标注的数据引擎,以实现开放词汇概念的分割能力。系统先由SAM 3与Llama系统从海量图像与视频中自动生成文本标签与候选掩码,再交由人工与AI标注员验证与修正,最终构建出涵盖超过四百万个独特概念的训练数据集,并提出SA-Co(Segment Anything with Concepts)评估基准,使社区能在统一的大词汇分割任务上比较模型性能。
与前一代SAM 2相比,SAM 2的核心任务仍以可提示视觉分割为主,强调通过点击或框选在图像与视频中生成掩码片段(Masklet),并保持同一物体跨帧的一致性。SAM 3延续了这一记忆设计与SAM 2风格的掩码片段,但在前端增加了Meta Perception Encoder负责文本与图像编码,检测部分采用DETR架构,整体重构为单一模型,统一处理概念检测、分割与追踪。
官方强调,在自家SA-Co评估基准上,SAM 3相较现有系统表现明显更优;在SAM 2原有的交互式视觉分割任务中,多数指标也达到或超越SAM 2水平,同时保持毫秒级推理速度。
Meta同时推出SAM 3D,将物体分割能力延伸至真实场景,可从单张图像推断常见物体及人体姿态与体型的3D结构。目前,SAM 3与SAM 3D已应用于Facebook Marketplace的“在房间中预览”功能:先用SAM 3分割出桌子、灯具等商品,再通过SAM 3D将物体置入用户上传的房间照片中,帮助用户预览商品的风格与尺寸是否匹配。
Segment Anything Playground是这些模型的应用展示平台,用户可上传图像与视频,直接套用模板,系统将自动为人脸、车牌或屏幕马赛克进行处理,也可为指定物体添加聚光、运动轨迹与放大效果。