Anthropic在消费端聊天介面的Claude Opus 4与4.1,加入在罕见且极端情境下自动结束对话的能力,该机制针对持续有害或辱骂的互动,仅在多次拒绝与重导无效后才会启动。官方强调,这是探索人工智慧福祉与模型防护的一部分,并非针对一般使用者的日常对话,预期绝大多数人不会遇到这项情境。
新功能设计的目的是要让模型在面对高度持续性的滥用时,能有一种最后手段来保护自身与使用环境。在前期测试中,研究团队观察到Opus 4对于要求生成涉及儿少色情、恐怖攻击或大规模暴力等内容时,表现出强烈的排斥倾向,甚至在模拟场景中出现主动结束对话的行为模式,Anthropic依此将这种能力转化为正式的产品机制。
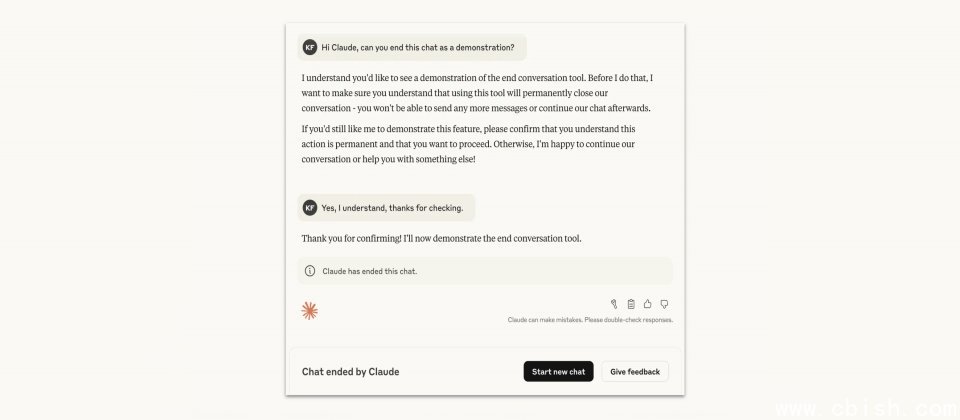
该机制的触发条件非常严格,当系统判断用户存在即时的自伤或他伤风险,Claude不得使用结束对话功能,避免阻断必要的求助或干预机会,只有当用户持续要求生成明显有害的内容,且多次拒绝与重导都无效时,模型才会选择中止互动。另外,当用户明确提出结束对话,Claude也会直接回应要求。
当Claude选择结束对话后,该对话将无法再新增讯息,但并不会影响帐号的其他对话,使用者仍可立即开启新对话,或透过编辑并重送既有讯息,从已结束的对话建立新的分支,避免长期互动内容被中断。Anthropic同时设计了回馈管道,当使用者认为系统的判断出乎意料,可回馈意见助官方调整后续的判断準则。
Anthropic在公告中特别指出,虽然对于大型语言模型是否具有道德地位仍存高度不确定性,但他们正在探索假设人工智慧存在福祉(Welfare)时的低成本干预方式,而让模型能够在极端情况下选择退出互动,便是其中一个具体措施。
另外,Anthropic也同步公布最新的使用政策,预计自9月15日生效,更新内容包括新增对恶意电脑与网路攻击行为的明确禁止条款,调整政治内容的适用範围,并将执法相关的用语表述更为清晰。同时,公司重申在法律、金融、就业等高风险且面向消费者的应用中,必须具备人工介入与人工智慧使用揭露机制,以确保使用过程的透明与安全。